
Multimedia is a combination of elements: text, graphics, images, audio, video, animation and any other media where every type of information can be represented, stored, transmitted and processed digitally.
Definitions
- Hypermedia: like Intro CD
- Multimedia Title: is a multimedia project being sold
- ASCII : American Standard Code for Information Interchange
- PCM : Pulse Coding Method
- JPEG : Joint Photographic Experts Group
- MPEG : Motion Photographic Experts Group
Media Classification
- Perception medium (Visual – Auditory )
- Representation medium (ASCII – PCM – JPEG – MPEG…)
- Presentation medium (Screen – Speakers – Keyboard – Camera…)
- Storage medium (CD – DVD – HDD)
- Transmission medium (Wire – Cable – Fiber Optics…)
A Multimedia System is characterized by computer-controlled, integrated production, manipulation, presentation, storage and communication of independent information, which is enclosed at least through a discrete and continuous medium.
A sequence of individual packets transmitted in a time-dependent fashion is called Data Stream. Packets can carry information of either continuous or discrete media.
Audiology is the discipline interested in manipulating acoustic signals that can be perceived by humans.
Sound is a physical phenomenon caused by vibration of materials, such as a violin string or a wood log. This type of vibration triggers pressure wave fluctuations in the air around the material. The pressure waves propagate in the air. We hear a sound when such a wave reaches our ear.
Sound has Frequency; the frequency represents the number of periods per second and is measured in hertz (Hz), Kilohertz (KHz), megahertz (MHz), Gigahertz (GHz)…etc.
Sound processes are classified by frequency range:
- Infrasonic 00 Hz to 20 Hz
- Audiosonic 20 Hz to 20 KHz (acoustic signals)
- Ultrasonic 20 KHz to 1 GHz
- Hypersonic 1 GHz to 10 THz
A sound has property called Amplitude, which humans perceive subjectively as loudness or volume.
The size of sound pressure level (SPL) is measured in decibels (dB).
| Sound Examples | Sound Pressure Level |
| Rustling of paper | 20 dB |
| Spoken language | 60 dB |
| Heavy road traffic | 80 dB |
| Rock band | 120 dB |
| Pain sensitivity threshold | 130 dB |
Audio Representation on Computers
- Computer measures the wave’s amplitude
- Takes the result and generates a sequence of sampling values (samples).
The Digitization process requires two steps.
1. Sampling
2. Quantization
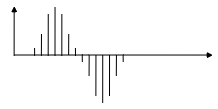
Sampling: the analog signal must be sampled. This means that only a discrete set of values is retained at time or space intervals.
The rate at which a continuous wave form is sampled is called the sampling rate.
The sampling rate is measured in Hz (like frequency). For example CDs are sampled at rate of 44100 Hz, which may appear to be above the frequency range perceived by humans.
Nyquist Sampling Theorem:
“The signal being sampled cannot contain any frequency components that exceed half of the sampling frequency”
Frequency range perceived by humans = 20 Hz – 20000 Hz
Audio CD sampling rate = 44100 Hz (22050 Hz / 2) Very close to human perception.
The Quantization process consists of converting a sampled signal into a signal that can take only a limited number of values.
An 8-bit quantization provides 256 possible values, while a 16-bit quantization in CD quality results in more than 65536 possible values.
MIDI: Musical Instrument Digital Interface, the MIDI protocol is an entire music description language in binary form.
Human Speech is based on spoken languages, which means it has a semantic content.
The brain corrects speech recognition errors because it understands the content, the grammar rules, and the phonetic and lexical word forms.
Computers can translate an encoded description of message into speech. This scheme is called Speech Synthesis. A particular type of synthesis is text-to-speech conversion.
Speech output deals with the machine generation of speech. A major challenge in speech output is how to generate these signals in real time for a speech output system to be able, for instance, to convert text to speech automatically.
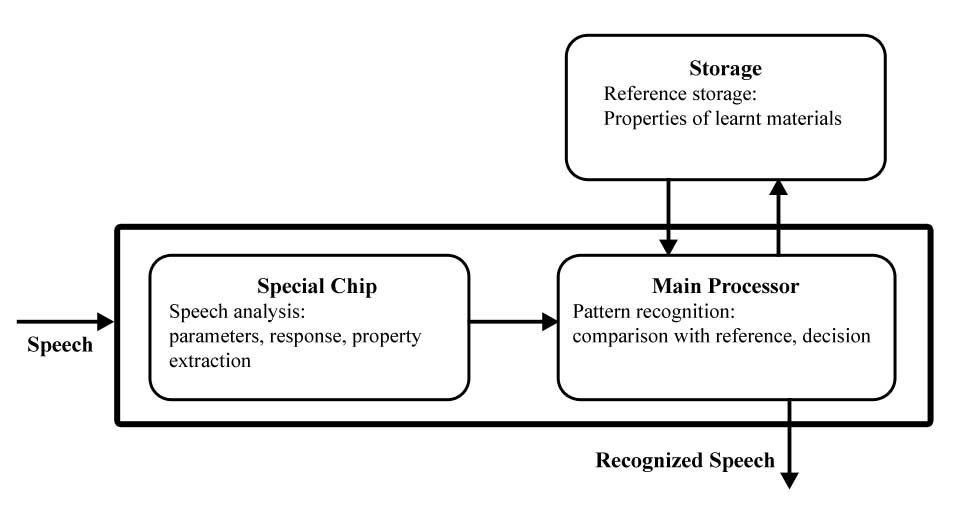
The components of a system that transforms an existing text into an acoustic signal are show in the following diagram:
Text Transcription Sound Script Synthesis Speech
Dictionary Sound transfer
- Translation of the text into corresponding phonetic transcription. Most use a lexicon, containing a large quantity of words.
- Convert the phonetic transcription into acoustic speech signal, where concatenation can be in the time or frequency range.
Speech input deals with the following scheme:
Verification
Who? Identification
Speech input What?
How?
In speech input we need to ask 3 questions:
Who? Human speech has certain speaker-dependent characteristics, which means that speech input can serve to recognize a speaker (e.g. Personal Identification Applications).
What? To detect the speech contents themselves. A speech sequence is normally input to generate piece of text (e.g. Speech-controlled typewriters).
How? How a speech sample should be studied (e.g. Lie Detector).
Speech Recognition: In combination with speech synthesis, it enables to implement media transformation. The primary quality characteristic of each speech recognition session is determined by certain probability to recognize a word correctly.
Factors that affect speech recognition:
Environmental noise, room acoustic, physical and psychical state of speaker…etc
A poor recognition rate is p=0.95, which corresponds to 5% wrongly recognized words. With a sentence of only three words, the probability that the system will recognize all triples correctly drops to:
p = 0.95 x 0.95 x 0.95 = 0.86
This small example shows that a speech recognition system should have a very high recognition rate.
Speech Transmission is a field relating to highly efficient encoding of speech signals to enable low-rate data transmission, while minimizing noticeable quality losses.
Pulse Code Modulation is a straightforward technique for digitizing an analog signal (waveform). It is a method of digitizing sound by sampling the sound signal at regular intervals (often 8 or 16 thousand times per second) and converting the level of the signal into a number.
Normally, sampling rate is as twice as the maximum frequency of the signal. This method is simple, it still meets the high quality demands stereo-audio signals in the data rate used for CDs:
44000 16 bit
Rate = 2 x ———— x —————– = 1764000 Bytes/s
S 8 bits/byte
As a side note, telephone quality requires only 64Kbit/s compared to 176400 bytes/s.
Differential Pulse Code Modulation (DPCM) achieves 56Kbit/s in at least equal quality, while Adaptive Pulse Code Modulation (ADPCM) enables a further reduction to 32Kbit/s
Source Encodingis an alternative method, where some transformations depend on the original signal type. For example, the suppression of silence in speech sequence is a typical example of transformation that depends entirely on the signal’s semantic.
Parametric systems use source encoding.
Graphics and Images are non-textual information that can be displayed or printed, but Graphics are different from Images.
Graphic Characteristics: Graphics are created in a graphics application and represented as objects such as lines, curves or circles. Attributes such as styles, width and color defines the appearance of graphics. They can be individually deleted, added, moved or modified later.
Images Characteristics: Images can be taken from the real world or virtual and are not editable in the sense given above. They are described as spatial arrays of values.
Pixel is the smallest addressable image element.
Bitmap is a set of pixels.
Their advantage is that no processing is necessary before displaying them, unlike graphics where the abstract definition must be processed first to produce a bitmap.
Capturing Graphics and Images