
You’ve learned that JavaScript is single-threaded; it can run only one task to completion at a time before starting a new task. But you’ve also seen examples of how certain resource intensive tasks can operate while other tasks run. So now you may be wondering “how is it that JavaScript can do only one thing at a time, when you just showed that it’s capable of managing multiple things at once?”
The environment in which JavaScript runs provides useful APIs to help it process more than one task at a time. Now you’re going to learn some of the inner details of how JavaScript is executed both synchronously and asynchronously, beginning with execution on the call stack.
You’re not expected to know every detail in order to be successful with the rest of this course. Knowing the basics of the JavaScript call stack, as well as the callback queue and event loop, will help you better understand the flow of your programs. In addition, the course refers back to these concepts at certain points. Happy learning! 🙂
What is the Call Stack, and Why Does it Matter?
JavaScript runtime (or host) environments like the browser and Node have a built-in interpreter that executes JavaScript code. It’s called the JavaScript engine. The engine has a mechanism, called the call stack, for keeping track of the order of function calls and where it is in a program at any given moment.
For example, the call stack manages the current function that’s being called, as well as any functions that are called from within that function, and other subsequent functions. The call stack itself can process only one function call at a time (it’s single-threaded). Consider the following image:

Anytime a function gets called, it gets pushed onto the call stack, and any functions called within the original function are pushed higher up onto the call stack. When a function is done executing, it gets popped off the top of the call stack, and the next function in the stack gets processed.
When the call stack finishes executing the last task and there’s nothing left to execute, the program finishes, leaving the call stack empty.
Consider the following code where func1() invokes two functions (func3 and func2) after it logs ‘Hi’ to the console:
function func3() {
console.log('Students!');
}
function func2() {
console.log('Treehouse');
}
function func1() {
console.log('Hi');
func2();
func3();
}
func1();
// Hi
// Treehouse
// Students!
The sequence below demonstrates how the above code is executed on the call stack:

func1()is invoked, which logsHito the consolefunc2()is pushed onto the stack, executes and logsTreehouseto the consolefunc2()is done executing, so it’s popped off the stackfunc3()is pushed onto the stack, invoked and logsStudents!to the consolefunc3()is done executing, so it’s popped off the stack- At this point
func1()is done executing all of its functions, so it’s popped off the stack - The call stack is empty
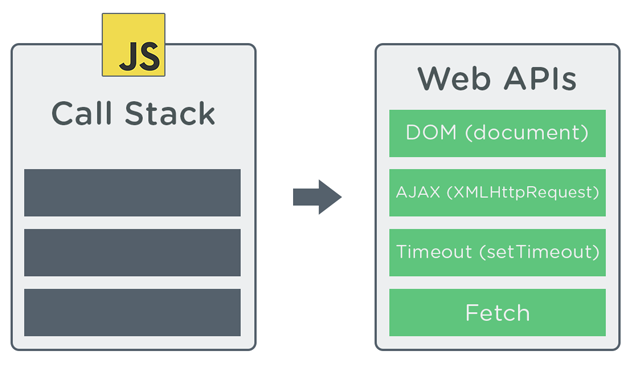
Web APIs
The call stack handles asynchronous tasks in a different way than synchronous tasks. Whenever the JavaScript environment encounters code that needs to run and execute at a later time, like a setTimeout() callback or a network request, that code is handed off to a special Web API that processes the async operation. Meanwhile, the call stack moves on to other tasks then revisits the async task when it’s ready to be dealt with.
It’s important to note that the asynchronous behavior of JavaScript does not come from the JavaScript engine itself. JavaScript engines like Chrome’s V8, for instance, do not have asynchronous capabilities. Asynchronicity actually comes from the runtime environment. Runtime environments (like web browsers and Node) provide APIs that let JavaScript run tasks asynchronously.
For example, async development in the browser (which is the focus of this course) happens in a number of places using Web APIs like setTimeout(), XMLHttpRequest (XHR), Fetch API, and the DOM event API.
Consider the code below code where func1() runs three tasks:
console.log('Hi')setTimeout()callsfunc2after1000ms- Invoke
func3
function func3() {
console.log('Students!');
}
function func2() {
console.log('Treehouse');
}
function func1() {
console.log('Hi');
setTimeout(func2, 1000)
func3();
}
func1();
// Hi
// Students!
// Treehouse
This time the results are different. The sequence below demonstrates how the above code is executed on the call stack:
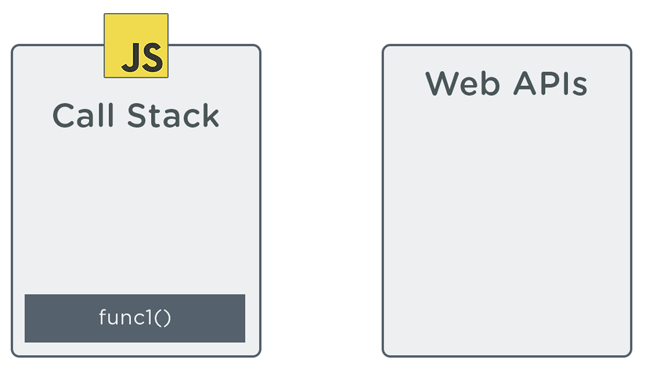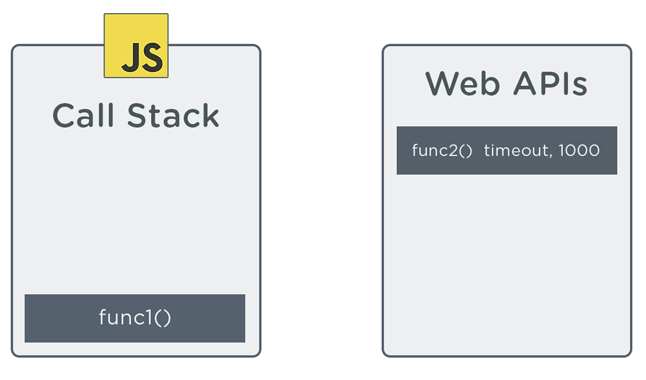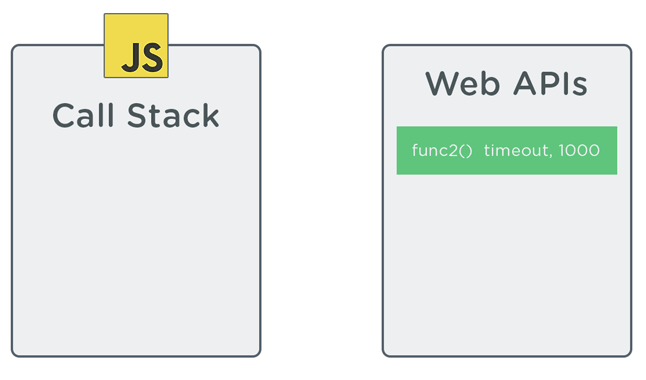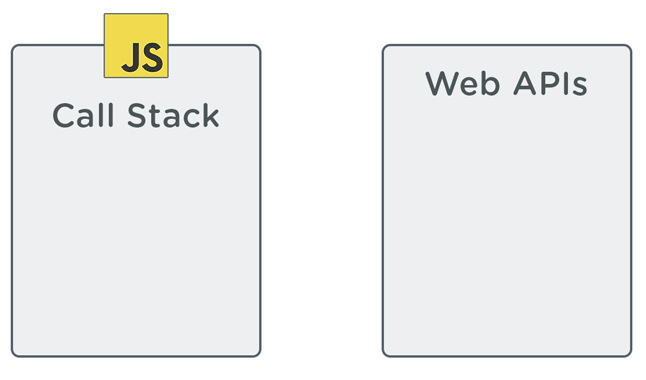
In the sequence, notice how the function passed to setTimeout (func2) is handed off to a web API immediately after setTimeout is pushed onto the call stack. The web API sets up a 1 second timer of sorts. setTimeout then gets popped off the stack, and the call stack moves on to execute func3 and finish executing func1. After setTimeout‘s 1 second delay is up, it appears on the call stack to be executed.
Where does the async callback go before being pushed onto the call stack? It doesn’t immediately go back into the call stack. Instead the callback gets pushed into something called the callback queue. You will learn about the callback queue and the one important job of the event loop, in the next step.